
Apache POI is the most common open source Java library used in the XLSX file parsing but it is very memory intensive, for file sizes ~50 MB it works well, but many times the requirement is to handle files which are in size range of Gigabytes.
Parsing these files in a way where memory footprint is very small, low resource usage and scalable to any file size by using the underlying structure of xlsx files is the goal of this article.
First of all lets see the underlying structure of an XLSX file. Create any xlsx file using MS excel and save it , after saving it change the extension to zip. Now Right click & open this zip with any archive manager you will see bundle of xml files like this :
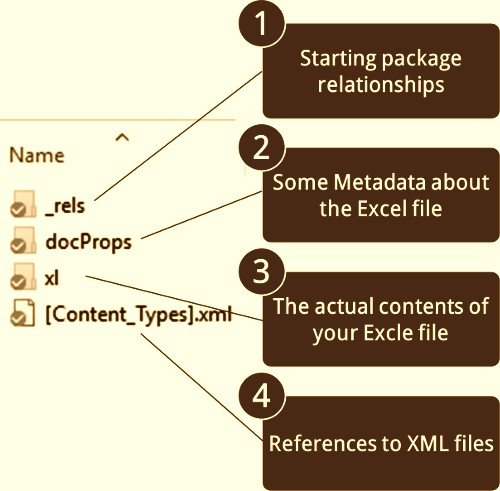
Inside xl/worksheets Folder you will find sheet1.xml, sheet2.xml etc,In there if you look into the contents of sheet, it will look something like this :
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<worksheet xmlns="http://schemas.openxmlformats.org/spreadsheetml/2006/main"
xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships"
xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006" mc:Ignorable="x14ac"
xmlns:x14ac="http://schemas.microsoft.com/office/spreadsheetml/2009/9/ac">
<dimension workbookViewId="0"/>
<sheetViews>
<sheetView tabSelected="1" workbookViewId="0"/>
</sheetViews>
<sheetFormatPr defaultRowHeight="16.5"/>
<sheetData>
<row r="1" spans="1:5">
<c r="A1" t="s">
<v>0</v>
</c>
</row>
</sheetData>
</worksheet>
When you open such file you will notice that all of the sheet data is inside <sheetData> element. For every row there is a <row> element, for every cell there is a <c> element. Finally, value of the cell is stored in a <v> element.
MS Excel uses internal table of unique strings (for performance optimizations). Zero is an index of that string in an internal table of strings and attribute t=”s” tells us that underlying type is a string, not a number. So where is the table of unique strings located? It is in “xl/sharedStrings.xml” XML file, and contains all strings used in entire workbook, not just specific worksheet.
So to sum it up in brief MS XLSX file structure is distributed within the zip package as :

Now lets dig into the Java coding part of parsing these sheet xmls using a SAX Parser. Below is the sample code generating the csv :
String dirPath = "path where you want to store generated csv";
File csvFile = new File(dirPath);
CSVWriter csvWriter = new CSVWriter(new FileWriter(csvFile));
OPCPackage opcPackage = OPCPackage.open("put xlsx file path");XSSFReader xssfReader = new XSSFReader(opcPackage);SharedStringsTable sharedStringsTable = xssfReader.getSharedStringsTable();XMLReader parser = XMLReaderFactory.createXMLReader("org.apache.xerces.parsers.SAXParser");ContentHandler sheetHandler = new SheetHandler(sharedStringsTable);
parser.setContentHandler(sheetHandler);// To look up the Sheet Name / Sheet Order / rID,
// Normally it's of the form rId# or rSheet#
InputStream inputStream = xssfReader.getSheetsData().next();
InputSource inputSheetSource = new InputSource(inputStream);
parser.parse(inputSheetSource);
inputStream.close();
Below sample is the Sheethandler SAX parser , to retrieve values using sharedStrings.
import org.apache.poi.openxml4j.exceptions.OpenXML4JException;
import org.apache.poi.openxml4j.opc.OPCPackage;
import org.apache.poi.ss.usermodel.Cell;
import org.apache.poi.ss.usermodel.Row;
import org.apache.poi.xssf.eventusermodel.XSSFReader;
import org.apache.poi.xssf.model.SharedStringsTable;
import org.apache.poi.xssf.streaming.SXSSFWorkbook;
import org.apache.poi.xssf.usermodel.XSSFRichTextString;
import org.xml.sax.Attributes;
import org.xml.sax.ContentHandler;
import org.xml.sax.InputSource;
import org.xml.sax.SAXException;
import org.xml.sax.XMLReader;
import org.xml.sax.helpers.DefaultHandler;
import org.xml.sax.helpers.XMLReaderFactory;private class SheetHandler extends DefaultHandler
{
private SharedStringsTable sharedStringsTable;
private String lastContents;
private boolean nextIsString;
private List<String> data; private SheetHandler(SharedStringsTable sst)
{
this.sharedStringsTable = sst;
}
public void startElement(String uri, String localName, String name,
Attributes attributes) throws SAXException
{
if (name.equals("row"))
{
data = new ArrayList<>();
}
// c => cell
if (name.equals("c"))
{
String cellType = attributes.getValue("t");
if (cellType != null && cellType.equals("s"))
{
nextIsString = true;
}
else
{
nextIsString = false;
}
}
// Clear contents cache
lastContents = "";
}public void endElement(String uri, String localName, String name) throws SAXException
{
if (name.equals("row") && !data.isEmpty())
{
csvWriter.writeNext(data.toArray(new String[data.size()]));
}
// Process the last contents as required.
// Do now, as characters() may be called more than once
if (nextIsString)
{
int idx = Integer.parseInt(lastContents);
lastContents = new XSSFRichTextString(sharedStringsTable.getEntryAt(idx)).toString();
nextIsString = false;
}
if (name.equals("v"))
{
data.add(lastContents);
}
if (name.equals("worksheet"))
{
// Note : this csv writer should not be used again
// after parsing , else it has to be reinstantiated.
try
{
csvWriter.close();
csvWriter = null;
}
catch (IOException e)
{
csvWriter = null;
}
}
public void characters(char[] ch, int start, int length)
throws SAXException
{
lastContents += new String(ch, start, length);
}
}
For light reading you can go through the following links :
- https://en.wikipedia.org/wiki/Office_Open_XML
- https://msdn.microsoft.com/en-us/library/office/gg278316.aspx




